

What is Fault-Error-Failure Cycle? : Key Concepts and Definitions
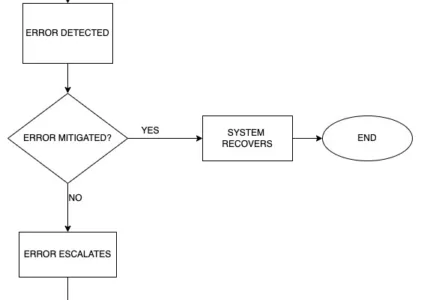
The fault-error-failure cycle is a fundamental concept in engineering and systems analysis that provides insights into the progression of events leading to system failures. To grasp the significance of this cycle and its implications, it is essential to understand the key concepts and definitions associated with it.
- Fault:
A fault refers to a defect or malfunction within a system component or process. It can arise from design flaws, manufacturing errors, environmental factors, or even wear and tear over time. Faults can manifest in various ways, such as a component not functioning as intended, an incorrect calculation, or a communication breakdown between system elements. - Error:
When a fault is activated and affects the behavior or performance of a system, it results in an error. Errors can occur due to human actions, incorrect assumptions, or the propagation of fault effects through the system. They represent deviations from the expected or desired system behavior. Errors may cause anomalies, inaccuracies, or inconsistencies within the system, potentially leading to undesired outcomes. - Failure:
If an error goes undetected or is not corrected in a timely manner, it can lead to a failure. A failure refers to the inability of a system to perform its intended function or deliver the expected results. Failures can range in severity, from minor disruptions or inconveniences to critical malfunctions or catastrophic events. System failures can have significant consequences, including safety risks, financial losses, or damage to reputation.
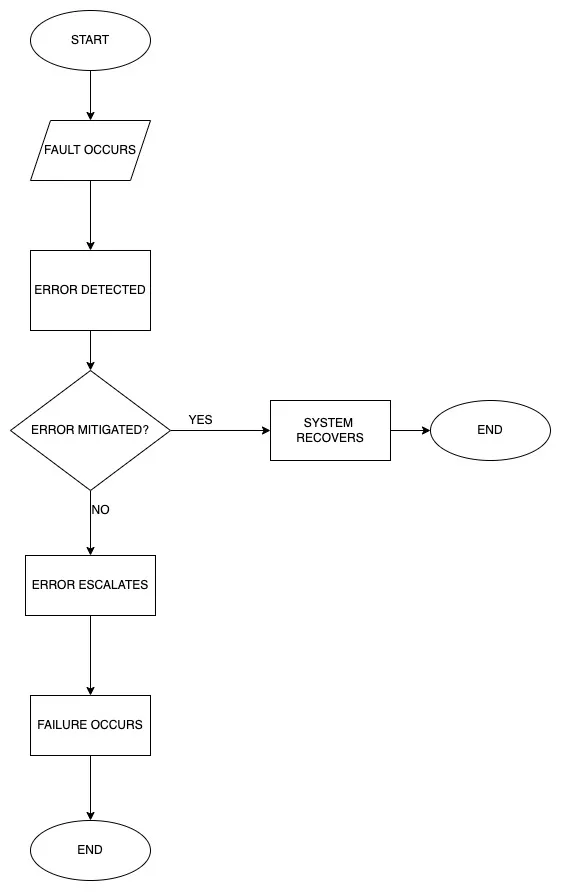
Understanding the fault-error-failure cycle involves recognizing the interconnectedness of these concepts. A fault can trigger an error, which, if left unaddressed, can escalate into a failure. Conversely, by effectively managing faults and errors, the likelihood of failures can be reduced, thereby enhancing system reliability and performance.
By comprehending these key concepts and definitions, engineers and analysts gain a solid foundation for identifying, analyzing, and mitigating faults and errors in systems. This knowledge is vital for implementing appropriate measures to detect and correct faults and errors promptly, minimizing the chances of failures and maximizing system reliability.
In the subsequent sections of this blog post, we will delve deeper into the fault-error-failure cycle, exploring strategies for fault detection, error prevention, and failure mitigation. Stay tuned to discover how you can leverage this understanding to enhance the resilience of your systems and minimize the risks associated with failures.
Table of Contents
Importance of Identifying and Addressing System Faults
Identifying and addressing system faults is of paramount importance when it comes to ensuring the reliability, safety, and optimal performance of any system. Here are key reasons why the identification and resolution of system faults are crucial:
- Preventing Cascading Effects: Faults in a system have the potential to propagate and affect other components or processes. If left undetected, these faults can lead to a chain reaction of errors and failures throughout the system. By identifying and addressing faults early on, it is possible to prevent the escalation of issues and mitigate the risk of widespread failures.
- Enhancing System Reliability: System faults can compromise the overall reliability of a system. By proactively identifying and rectifying faults, engineers can improve the dependability and availability of the system. This is particularly important for critical infrastructure, such as transportation networks, power grids, and healthcare systems, where failures can have severe consequences.
- Minimizing Downtime and Costs: Faults that result in system failures often lead to costly downtime and repairs. Unplanned system outages can disrupt operations, cause productivity losses, and incur financial expenses for repairs and maintenance. By promptly identifying and addressing faults, organizations can minimize downtime, optimize system performance, and avoid unnecessary expenditures.
- Ensuring Safety: Faults in safety-critical systems, such as aircraft, medical devices, or nuclear power plants, can have life-threatening implications. Identifying and addressing faults is essential for maintaining the safety and well-being of individuals who interact with these systems. By actively monitoring and resolving faults, potential hazards can be mitigated, and the risk to human lives can be minimized.
- Improving Customer Satisfaction: Customers and end-users expect reliable and efficient performance from the systems they rely on. Identifying and resolving faults before they escalate into failures is key to meeting customer expectations. By ensuring the proper functioning of systems, organizations can enhance customer satisfaction, build trust, and maintain a positive reputation.
- Enabling Proactive Maintenance: Identifying system faults allows for proactive maintenance strategies. Instead of waiting for failures to occur, proactive maintenance involves monitoring and addressing faults in advance, minimizing the likelihood of unexpected breakdowns and optimizing system longevity. This approach reduces downtime, extends equipment lifespan, and optimizes maintenance costs.
The identification and timely resolution of system faults are critical for maintaining system reliability, safety, and performance. By proactively addressing faults, organizations can prevent cascading effects, enhance system dependability, minimize downtime and costs, ensure safety, improve customer satisfaction, and enable proactive maintenance practices. Through effective fault management, organizations can significantly mitigate risks and achieve more resilient and efficient systems.
Exploring the Role of Errors in the Fault-Error-Failure Cycle
Errors play a significant role in the fault-error-failure cycle, influencing the progression from faults to system failures. Understanding the role of errors is crucial for effective fault management and failure prevention. Here are key aspects to consider:
- Error Activation: Errors are triggered when a fault is activated within a system. A fault, such as a component malfunction or a process deviation, introduces the potential for errors to occur. The presence of a fault alone does not necessarily lead to an error. However, when the fault interacts with other system elements or processes, it can manifest as an error.
- Error Propagation: Once an error is activated, it has the potential to propagate throughout the system. Errors can spread through various pathways, affecting interconnected components or processes. This propagation can lead to the amplification of errors and the emergence of new errors in different parts of the system. Understanding how errors propagate is crucial for identifying and addressing their root causes effectively.
- Error Effects: Errors can have diverse effects on system behavior and performance. They can cause deviations from the expected or desired operation, leading to inaccuracies, anomalies, or inconsistencies. Errors may result in incorrect calculations, faulty communication, or disruptions in data flow. These effects can compromise the reliability, efficiency, and safety of the system.
- Error Detection: Detecting errors is a critical step in the fault-error-failure cycle. Timely error detection allows for proactive measures to be taken before errors escalate into failures. Various error detection techniques, such as monitoring systems, sensors, or software algorithms, are employed to identify deviations from normal operation. Effective error detection helps trigger corrective actions and prevents the progression of errors.
- Error Correction: Once errors are detected, appropriate measures can be taken to correct them. Error correction involves understanding the underlying causes of errors, rectifying the faults responsible for their occurrence, and restoring the system to its desired state. Prompt and accurate error correction is essential for preventing the accumulation of errors, mitigating their impact, and averting potential failures.
- Error Prevention: Understanding the role of errors also enables proactive error prevention strategies. By analyzing the root causes of errors and addressing them at their source, organizations can implement design improvements, process optimizations, and quality control measures to minimize the occurrence of errors in the first place. Error prevention helps break the cycle of faults leading to errors and eventually resulting in failures.
By comprehending the role of errors in the fault-error-failure cycle, engineers and analysts can implement robust error detection and correction mechanisms. This proactive approach to error management contributes to increased system reliability, improved performance, and enhanced overall system resilience. By addressing errors effectively, organizations can break the cycle of failures and establish more dependable and efficient systems.
Preventing Failures: Strategies for Effective Error Detection and Correction
Preventing failures in systems requires effective error detection and correction strategies. By proactively identifying and addressing errors, organizations can minimize the risk of failures and enhance system reliability. Here are some key strategies to consider:
- Robust Monitoring and Testing: Implementing robust monitoring and testing mechanisms is crucial for error detection. Continuous monitoring of system behavior, performance metrics, and key indicators allows for the early identification of deviations or anomalies. This can be achieved through the use of sensors, automated checks, or real-time data analysis. Comprehensive testing, including unit testing, integration testing, and system-level testing, helps uncover potential errors before they impact the system’s operation.
- Redundancy and Fault Tolerance: Incorporating redundancy and fault tolerance measures is an effective strategy to mitigate errors. Redundancy involves duplicating critical components, processes, or data to provide backup options in case of failures. Fault tolerance mechanisms, such as graceful degradation or failover systems, ensure that the system can continue functioning even if certain components or processes encounter errors. These strategies help maintain system operation and minimize the impact of errors.
- Error Logging and Alert Systems: Implementing error logging mechanisms and alert systems enables prompt error detection and response. Errors and their associated details should be logged systematically, allowing for analysis and identification of recurring patterns. Setting up alert systems that trigger notifications when critical errors occur enables timely intervention and corrective actions. This approach helps address errors before they lead to failures and enables proactive maintenance.
- Root Cause Analysis: Conducting thorough root cause analysis is essential for effective error correction. When errors are detected, it is crucial to investigate their underlying causes to prevent their recurrence. Root cause analysis involves examining system design, components, processes, and external factors to identify the fundamental issues that led to the errors. By addressing the root causes, organizations can implement targeted corrective actions and prevent similar errors in the future.
- Continuous Improvement and Learning: Embracing a culture of continuous improvement and learning is vital for error prevention. Organizations should foster an environment that encourages feedback, knowledge sharing, and lessons learned from past errors. Regular reviews and evaluations of system performance and error management practices help identify areas for improvement and enable the implementation of corrective measures. By continuously learning and adapting, organizations can proactively prevent errors and enhance system resilience.
- Training and Skill Development: Investing in training and skill development for personnel involved in system operation and maintenance is crucial. Ensuring that individuals possess the necessary knowledge and expertise to detect and address errors effectively enhances the overall error management capabilities of the organization. Training programs should cover error detection techniques, error correction procedures, and best practices for error prevention.
By implementing these strategies, organizations can enhance their error detection and correction capabilities, significantly reducing the likelihood of failures. Proactive error management not only improves system reliability but also optimizes system performance, minimizes downtime, and enhances customer satisfaction. Through continuous improvement and a proactive approach to error prevention, organizations can establish robust and resilient systems that operate with high efficiency and dependability.
Case Studies: Real-World Examples of the Fault-Error-Failure Cycle
Case studies provide valuable insights into the fault-error-failure cycle and how it manifests in real-world scenarios. By examining actual incidents, we can better understand the impact of the cycle and learn from these experiences. Here are a few examples of notable case studies highlighting the fault-error-failure cycle:
Three Mile Island Nuclear Accident:
In 1979, the Three Mile Island nuclear power plant in the United States experienced a partial meltdown due to a combination of equipment malfunctions and operator errors. The incident started with a small fault in a valve, which went unnoticed. The fault led to an error in cooling system operations, resulting in a series of errors and misinterpretations by the operators. Eventually, these errors contributed to a failure in the reactor core cooling system, leading to a partial meltdown. The accident highlighted the critical role of error detection, operator training, and effective communication in preventing failures in complex systems.
Deepwater Horizon Oil Spill:
The Deepwater Horizon oil spill in 2010 was one of the largest environmental disasters in history. The incident occurred due to a combination of design flaws, equipment failures, and human errors. A fault in the blowout preventer (BOP) system, designed to prevent well blowouts, led to an error during a critical operation. The error resulted in a failure of the BOP system, causing the uncontrolled release of oil. The incident underscored the importance of thorough risk assessments, robust safety measures, and proper maintenance to prevent faults from escalating into failures with catastrophic consequences.
Therac-25 Radiation Therapy Accidents:
The Therac-25 radiation therapy machine accidents in the 1980s serve as a stark example of software and design-related faults leading to failures. The machine had a software bug that allowed the delivery of high doses of radiation, resulting in several patient injuries and deaths. The faults in the software, combined with inadequate error detection and poor user interface design, contributed to the errors that led to the failures. This case study emphasized the significance of rigorous software testing, thorough quality assurance processes, and effective user interfaces to prevent faults and errors that can have severe consequences. Read more about it.
Ariane 5 Rocket Failure:
In 1996, the inaugural flight of the Ariane 5 rocket ended in a catastrophic failure just seconds after launch. The failure was attributed to a software-related fault known as an integer overflow. The software code, reused from the predecessor Ariane 4 rocket, had not been adapted to the increased speed of the Ariane 5. This fault caused a critical error in the rocket’s guidance system, leading to its self-destruction. The incident underscored the importance of rigorous testing, careful code review, and thorough validation when reusing software components or transitioning to new systems.
Knight Capital Group Trading Error:
In 2012, Knight Capital Group, a financial services firm, experienced a software-related trading error that resulted in substantial financial losses. A faulty software update caused the trading system to generate a large number of erroneous orders, leading to excessive and unintended trading activity. Within minutes, the company incurred losses amounting to hundreds of millions of dollars. The incident highlighted the need for robust testing, careful deployment procedures, and effective error handling mechanisms to prevent software-related errors with significant financial consequences.
Volkswagen Diesel Emissions Scandal:
The Volkswagen diesel emissions scandal, which came to light in 2015, involved software manipulation to deceive emissions tests. Volkswagen had developed software known as “defeat devices” that detected when the car was being tested and altered the engine’s performance to meet emission standards. However, under normal driving conditions, the vehicles emitted pollutants far above the permissible levels. The scandal exposed the ethical implications of software manipulation and emphasized the importance of transparency, compliance, and accountability in software development and testing.
Heartbleed Vulnerability:
Heartbleed was a critical security vulnerability discovered in April 2014 within the widely used OpenSSL cryptographic software library. The fault allowed an attacker to exploit a flaw in the implementation of the Transport Layer Security (TLS) heartbeat extension, which could lead to the exposure of sensitive data stored in the server’s memory.
The Heartbleed vulnerability affected a large number of websites, servers, and networking equipment globally, potentially compromising user data, such as passwords, encryption keys, and other sensitive information. The flaw allowed attackers to request additional data from the server’s memory, bypassing security measures, and potentially extracting confidential data without leaving any trace of the attack.
Once the Heartbleed vulnerability was discovered, the security community and organizations took immediate action to address the issue. The OpenSSL project released an updated version that patched the vulnerability, and organizations promptly applied the fix to their systems. Website owners and service providers also revoked and reissued SSL/TLS certificates to ensure the security of their communications.
The widespread impact of Heartbleed raised awareness about the importance of secure communication protocols, encryption, and data protection practices. It prompted organizations to adopt more stringent security measures, such as increased use of secure coding practices, regular vulnerability assessments, and improved incident response capabilities.
Shellshock Vulnerability:
Shellshock, also known as the Bash bug, was a critical security vulnerability discovered in September 2014 within the Bash (Bourne Again SHell) command-line interpreter, which is commonly used in Unix-based operating systems. The flaw allowed attackers to execute arbitrary commands and gain unauthorized access to systems.
The Shellshock vulnerability affected a wide range of systems, including web servers, network devices, and embedded systems. Exploiting the vulnerability involved manipulating environment variables to execute malicious commands within the Bash shell. Attackers could use this to launch various attacks, including remote code execution, privilege escalation, and data exfiltration.
Once the Shellshock vulnerability was discovered, the software community and organizations acted swiftly to address the issue. Patches and updates were released to fix the vulnerability in affected software versions. System administrators and IT teams applied these updates to secure their systems and prevent potential exploitation.
The Shellshock incident highlighted the importance of regularly updating software and promptly applying security patches. It also underscored the need for strong access controls, network segmentation, and monitoring systems to detect and prevent unauthorized activities. Additionally, it emphasized the significance of thorough vulnerability scanning and penetration testing to identify and address potential security weaknesses.
The Shellshock vulnerability led to increased awareness of the importance of secure coding practices, vulnerability management, and incident response capabilities. It prompted organizations to prioritize security testing and secure development practices, including conducting code reviews, using secure coding standards, and implementing robust security measures in software development lifecycles.
Enhancing System Resilience: Best Practices for Failure Prevention
Enhancing system resilience is crucial for preventing failures and ensuring the reliable operation of critical systems. By implementing best practices for failure prevention, organizations can minimize the risk of faults, errors, and failures. Here are some key practices to consider:
- Robust System Design:
Start by building robust system designs that incorporate redundancy, fault tolerance, and fail-safe mechanisms. Redundancy involves duplicating critical components or systems to provide backup options in case of failures. Fault tolerance ensures that the system can continue operating even if certain components encounter errors. Fail-safe mechanisms help minimize the impact of failures by implementing safety measures that prevent catastrophic consequences. - Thorough Testing and Validation:
Conduct comprehensive testing and validation processes throughout the system development lifecycle. This includes unit testing, integration testing, system testing, and acceptance testing. Emphasize the identification and resolution of potential faults, bugs, and vulnerabilities. Use a combination of functional testing, performance testing, and security testing to ensure that the system operates as intended and can withstand different scenarios and stress conditions. - Continuous Monitoring and Analytics:
Implement robust monitoring and analytics capabilities to proactively detect anomalies and potential failures. Continuous monitoring of system metrics, performance indicators, and error logs helps identify deviations from normal behavior. Leverage advanced analytics and machine learning techniques to analyze data patterns, detect anomalies, and predict potential failures. This enables proactive intervention and preventive measures before failures occur. - Effective Change and Configuration Management:
Establish proper change and configuration management practices to minimize the introduction of faults during system updates, upgrades, or modifications. Implement change control processes to assess the impact of proposed changes, perform rigorous testing, and validate the changes before deployment. Ensure that configurations are properly documented, and maintain version control to track changes and facilitate rollback if necessary. - Robust Security Measures:
Implement strong security measures to protect the system from external threats and potential vulnerabilities. Apply secure coding practices, perform regular security audits and penetration testing, and keep software and firmware up to date with the latest security patches. Enforce access controls, encryption, and authentication mechanisms to safeguard sensitive data and prevent unauthorized access. - Training and Skill Development:
Invest in training and skill development programs for personnel involved in system operation and maintenance. Ensure that individuals possess the necessary knowledge and expertise to effectively manage and prevent failures. Provide training on error detection techniques, incident response procedures, and best practices for system resilience. Foster a culture of continuous learning and knowledge sharing to stay updated with evolving technologies and emerging threats. - Incident Response and Lessons Learned:
Develop a robust incident response plan that outlines procedures for identifying, containing, and resolving failures. Establish clear communication channels and escalation paths to address failures promptly and minimize their impact. After incidents occur, conduct thorough postmortem analyses to identify the root causes, assess the effectiveness of existing prevention measures, and implement corrective actions. Capture lessons learned and share them across the organization to enhance system resilience.
The Future of Systems Engineering: Mitigating the Fault-Error-Failure Cycle
The fault-error-failure cycle has been a longstanding challenge in systems engineering. However, advancements in technology and evolving practices offer promising avenues for mitigating this cycle and improving overall system resilience. Here are some insights into the future of systems engineering and its role in mitigating the fault-error-failure cycle:
- Model-Based Systems Engineering (MBSE):
MBSE is an approach that utilizes models to represent and analyze complex systems throughout their lifecycle. By using formal models, engineers can identify potential faults, simulate system behavior, and assess the impact of changes before implementation. MBSE allows for early detection of errors and facilitates proactive mitigation strategies, reducing the likelihood of failures. - Automated Verification and Validation:
Emerging techniques in automated verification and validation (V&V) enable more thorough and efficient testing of complex systems. Formal methods, model checking, and automated test generation can help detect faults and uncover potential errors that may otherwise go unnoticed. By automating V&V processes, engineers can enhance the reliability and quality of systems while reducing the time and effort required for manual testing. - Machine Learning for Anomaly Detection:
Machine learning algorithms can analyze vast amounts of system data and identify patterns that may indicate faults or errors. By training models on historical data, anomalies and deviations from normal behavior can be detected in real-time, enabling proactive measures to prevent failures. Integrating machine learning techniques with monitoring systems enhances early fault detection, allowing for timely intervention and system resilience. Read about: Benefits of Using Artificial Intelligence in Marketing: The Future of Digital Advertising - Proactive Risk Assessment:
Future systems engineering practices will increasingly focus on proactive risk assessment and management. Utilizing techniques like Failure Modes and Effects Analysis (FMEA) and Fault Tree Analysis (FTA), engineers can identify potential faults, their causes, and the impact on system performance. By identifying critical failure paths and implementing risk mitigation strategies early on, the fault-error-failure cycle can be effectively disrupted. - Cybersecurity by Design:
As digital systems become more interconnected, cybersecurity plays a critical role in mitigating the fault-error-failure cycle. Implementing cybersecurity measures from the inception of system design, such as secure architecture, encryption, and intrusion detection, enhances system resilience against cyber threats. Integrating security considerations into systems engineering processes ensures that potential faults and vulnerabilities are addressed proactively. - Continuous Monitoring and Adaptive Systems:
The future of systems engineering involves continuous monitoring and adaptive systems that can detect and respond to faults and errors in real-time. By leveraging sensors, data analytics, and automation, systems can dynamically adjust their behavior to prevent failures. Implementing feedback loops and closed-loop control mechanisms allow for self-correction and adaptation, minimizing the impact of faults and errors on system performance. Read about: Top 15 Benefits of Cloud Native Services and Real-World Use Cases from Industry Leaders - Organizational Culture and Collaboration:
Mitigating the fault-error-failure cycle requires a collaborative and learning-oriented organizational culture. Emphasizing open communication, knowledge sharing, and cross-disciplinary collaboration allows for early detection and resolution of faults and errors. Encouraging a culture that values transparency, accountability, and continuous improvement fosters an environment where failures are viewed as learning opportunities, leading to more resilient systems.
Conclusion: Harnessing the Power of the Fault-Error-Failure Cycle for Reliable Systems
while the fault-error-failure cycle presents challenges and risks, harnessing its power can lead to the development of more reliable and resilient systems. By understanding the underlying concepts and definitions of faults, errors, and failures, organizations can take proactive measures to prevent and mitigate their occurrence.
Identifying and addressing system faults is crucial for maintaining system integrity and performance. By implementing effective fault detection mechanisms, organizations can minimize the likelihood of faults propagating into errors and failures. Thorough testing, continuous monitoring, and robust security measures are essential for preventing faults from escalating and causing system-wide failures.
Errors, although undesirable, play a vital role in the fault-error-failure cycle. They serve as indicators of underlying faults and provide opportunities for improvement. By embracing errors as learning opportunities and promoting a culture of continuous improvement, organizations can enhance their systems’ resilience and prevent future failures.
Effective error detection and correction strategies are key to breaking the fault-error-failure cycle. Utilizing techniques such as thorough testing, fault injection, and error handling mechanisms, organizations can identify and rectify errors before they manifest as failures. Investing in comprehensive training and skill development programs for personnel involved in system operation and maintenance is crucial for effective error management.
Real-world case studies, such as Heartbleed and Shellshock, emphasize the importance of addressing software-related faults and vulnerabilities. These incidents highlight the significance of regular software updates, security audits, and rigorous testing to prevent faults from being exploited and leading to widespread failures.
Looking ahead, the future of systems engineering holds promising advancements for mitigating the fault-error-failure cycle. Model-based systems engineering, automated verification and validation, machine learning, and proactive risk assessment techniques offer valuable tools for identifying and addressing faults and errors early in the system lifecycle. Incorporating cybersecurity measures, continuous monitoring, and adaptive systems ensures that potential faults and vulnerabilities are proactively managed.
By harnessing the power of the fault-error-failure cycle, organizations can build reliable and resilient systems that withstand challenges and operate with integrity. It requires a proactive mindset, continuous learning, and a collaborative culture to embrace faults and errors as opportunities for improvement. With these efforts, organizations can break the cycle, enhance system reliability, and deliver solutions that inspire trust and confidence in their users.